VisualisierungzukünftigerKonzeptemitBody-inputundKI

Wir haben alle erleben den Hype um die neuen KI-Tools mit, die im vergangenen Jahr die Kreativbranche eroberten. Die disruptive Technologie zwang jeden in diesem Beruf dazu, sich von den neuen Workflows entweder befähigt oder bedroht zu fühlen. bewirkt, dass sich viele ihrem Beruf durch die neu entstehende Arbeitsabläufe entweder befähigt oder bedroht fühlen. Für uns war es klar, dass wir die Technologie mit unseren Erfahrungen bei der Gestaltung interaktiver Installationen verknüpfen wollten. Dabei treibt uns die Möglichkeit, den Nutzern etwas an die Hand zu geben, mit dem sie ihre eigene Kreativität sofort ausleben können. Wir zielten darauf ab einen kollaborativen Arbeitsablauf zwischen dem User und der KI zu definieren, der geführt wird, aber dennoch genügend kreative Freiheit lässt. Eine intuitive Interaktion und die Fähigkeit, den eigenen Körper als Gestaltungswerkzeug zu nutzen, waren für unsere Anwendung unerlässlich.
Lies den Artikel auch auf behance.

Future telling
In der UI- und visuellen Gestaltung wollten wir die günstige, aber auch übermäßig techno-optimistische Sichtweise der meisten Menschen auf neue technologische Entwicklungen widerspiegeln. Einige jagen innovativen Ideen hinterher, in der Hoffnung, dass sie alle bestehenden Probleme lösen werden. Daher schien die stilistische Wahl, Elemente aus dem Kartenlegen mit Tarotkarten zu integrieren, passend. Die dekorativen Elemente, die von der Art nouveau inspiriert waren, lieferten auch eine starke Analogie für die neuartige Ästhetik der AI-Kunst.

Body-to-image Generierung
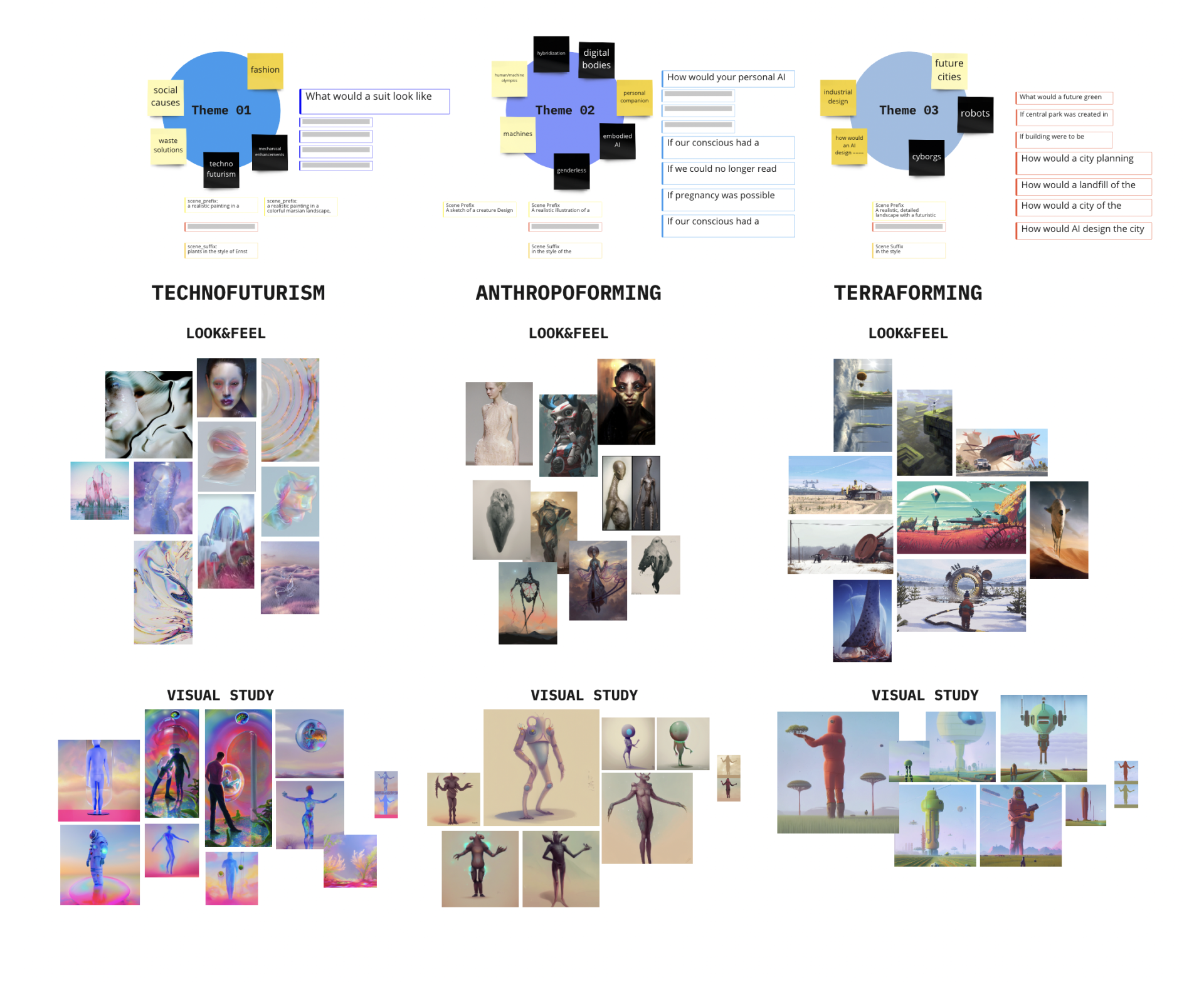
Als Deep-Learning-Generator entschieden wir uns für Stable-Diffusion, da es uns erlaubte, eine große Kontrolle über die Generierungsparameter zu haben. Anschließend haben wir einen konzeptionellen und visuellen Rahmen definiert, um den Benutzer und die Bildgenerierung zu einem zusammenhängenden Ergebnis zu führen. Die Hauptaufgabe bestand darin, Fragen über ein individuelles, spekulatives Zukunfts-Produkt zu beantworten und die Antwort über eine Touch-Pad einzugeben. Um die Nutzererfahrung zu optimieren, haben wir jedem Besucher dabei drei Dachthemen gegeben. Die Antwort des Users wurde dann als Text-zu-Bild-Prompt für die Bildgenerierung verwendet. Für jedes Dachthema haben wir eine individuelle visuelle Richtung entwickelt.
Die Kontrolle der Bildverteilung in eine bestimmte Richtung ist der zeitaufwendigste und herausforderndste Teil bei der Verwendung von Deep-Learning-Tools. Neben einem durchdachten Prompt-Design und einer Sammlung gut funktionierender Begriffe ist es wichtig, flexibel hinsichtlich des Ergebnisses zu sein. Je genauer das vorgestellte Konzept beschrieben wird, desto genauer wird die Bild-Generierung. Dabei wird empfohlen, mit überlappenden Konzepten zu arbeiten, da nur eine begrenzte Anzahl von Pixeln für die Generierung verwendet werden kann. Zu viele widersprüchliche Ideen konkurrieren um einen begrenzten Platz. Daher haben wir einen Prompt-Prä- und -Suffix entwickelt, der mit dem Dachthema verbunden ist. Diese Prompts waren im Frontend nicht sichtbar und halfen uns, für jedes Thema ein zusammenhängenden Look and Feel zu schaffen, indem sie sich um den vom Benutzer eingegebenen Prompt legten. Die während der Konzeptphase erstellten Moodboards halfen uns, die am besten passenden Begriffe zu finden.

Zusätzlich zur Texteingabe haben wir auch mit Eingabebildern für den Vorder- und Hintergrund gearbeitet. Auf diese Weise haben wir mehr Variationen für den Rauschunterdrückungsprozess während der Bildverteilung geschaffen. Die Eingabebilder ermöglichten es uns auch, Farbschemata für jedes Thema festzulegen.
Unser wichtigster Input war die Form des Benutzer-Körpers, die über eine Infrarotkamera getracked wurde. Auf diese Weise konnte der Nutzer die Gesamtkomposition spielerisch beeinflussen. Der Körper fungierte als Maske und enthüllte letztlich das definierte Vordergrundbild. In der Benutzeroberfläche konnten die User die Form ihres Körpers als Schatten-Silhouette sehen. Die Einflussnahme war nach ein paar Sekunden sichtbar und zeigte das generierte Ergebnis. Nachdem wir uns mit verschiedenen Text-Prompts in Kombination mit ihrem eigenen Körper-Input ausprobiert haben, konnten die drei favorisierten Ergebnisse ausgewählt und der Sammlung fiktiver Zukunftsszenarien im Idle-Modus hinzugefügt werden.
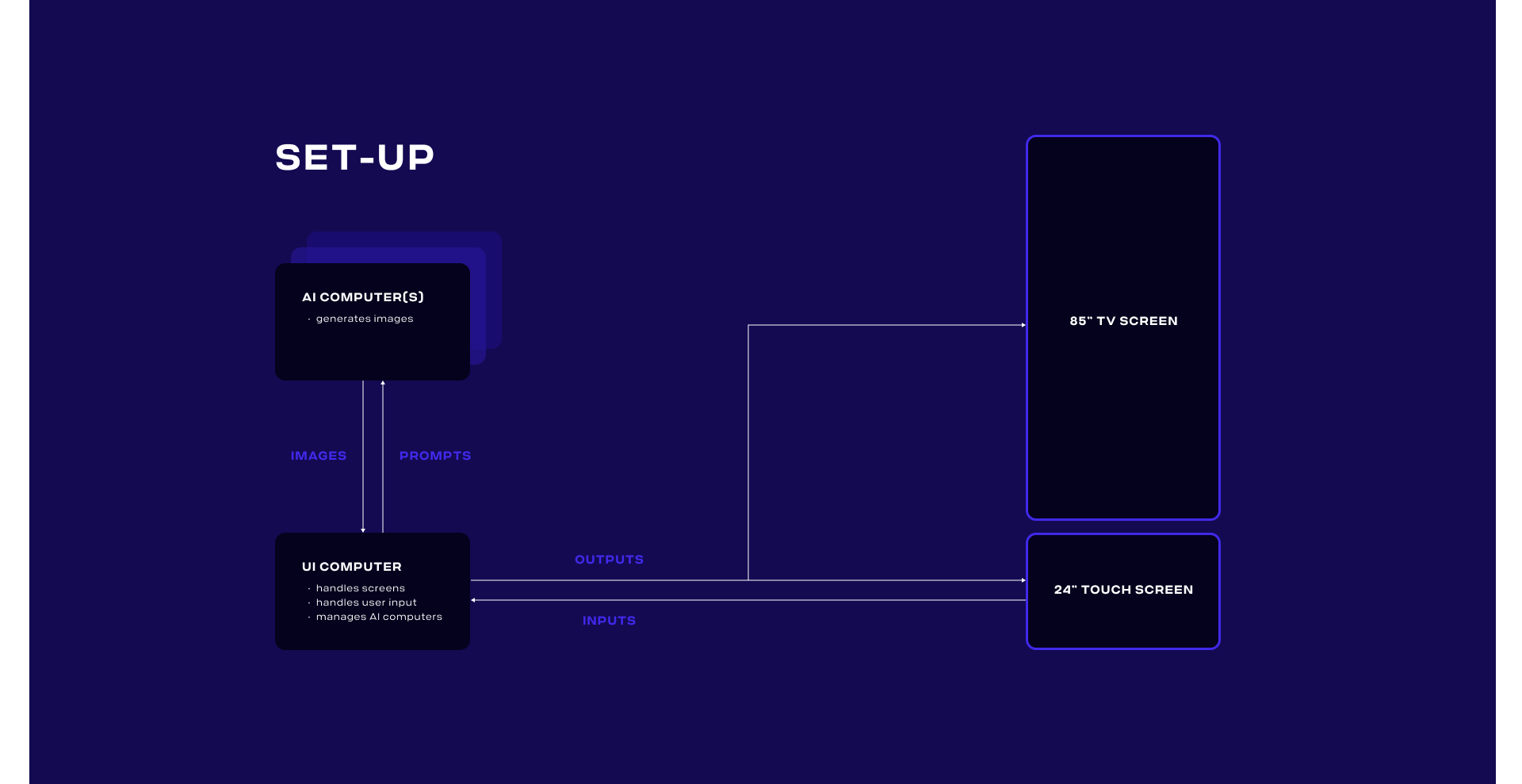
Technische Hürden
Das direkte Feedback an den User zu seinen/ihren Eingaben war ein entscheidender Aspekt der Experience. Daher haben wir die Bildgenerierung auf einen dedizierten High-End-PC aufgeteilt, auf dem eine selbstgehostete Stable Diffusion-Installation mit Einstellungen ausgeführt wurde. Dies ermöglichte uns, ein Bild innerhalb von 4-8 Sekunden zu rendern. Der User interagierte mit einem separaten Client, der die Benutzeroberfläche rendern und die Render-Anweisungen verwalten konnte. Durch Hinzufügen weiterer Render-PCs hätten wir die Bildwiederholrate sogar noch weiter erhöhen können.
Das finale Setup Einrichtung ermöglichte es den Usern, aus ihren generierten Bildern eine eigene Animation zu erstellen. Aufgrund langer Renderzeiten und des Mangels an direktem Animation-Support im ausgewählten Stable-Diffusion-Modell war dies jedoch unpraktisch.
Eine Idee mit Business-Potential
Die Fictional-Future Experience wurde im Rahmen unserer Demodern-Showrooms vorgeführt. Und sorgte dabei für so viel Interesse, dass unser Kunde MINI beschloss, die Technologie im Rahmen der Sydney WorldPride Kampagne für das MINIverse zu integrieren, wo User ihre eigenen LGBTQAI+-Themenbilder aus dem MINIverse in ihrem Webbrowser oder Mobilgerät generieren konnten.
